Tutto il contenuto di un sito gestito con SPIP è inserito in un database mySQL. Per presentare le informazioni ivi contenute ai visitatori del sito è quindi necessario realizzare la procedura che consiste nel leggere le informazioni, ad organizzarle e a impaginarle, al fine di mostrare una pagina HTML nel browser Web.
Se non si utilizza un programma avanzato di gestione dei contenuti come SPIP questa operazione è abbastanza onerosa:
- bisogna conoscere la programmazione PHP e MySQL, e scrivere delle "routine" relativamente complesse;
- integrare queste routine in una impaginazione elaborata con l’HTML è molto impegnativo;
- è necessario sviluppare a partire da zero un’interfaccia affinché gli utenti autorizzati possano modificare il contenuto del database;
- bisogna considerare i problemi di performance: l’uso sistematico al codice MySQL e PHP è avido di risorse, rallenta la navigazione e, in casi estremi, provoca il blocco del server Web.
SPIP propone una soluzione completa per aggirare queste difficoltà:
- l’impaginazione del sito è fatta tramite pagine HTML chiamate modelli di layout, contenenti istruzioni semplificate che permettono di indicare dove e come disporre nella pagina le informazioni estratte dal database;
- un sistema di cache permette di immagazzinare ogni pagina e quindi di evitare di provocare delle chiamate al database per ogni visita. Non solo, il carico del server è ridotto, la velocità risulta ampiamente accelerata, inoltre un sito sotto SPIP può essere consultato anche quando il database MySQL si pianta;
- un’“area riservata” che permette agli amministratori e ai redattori di gestire tutti i dati del sito.
Per ogni tipo di pagina, un modello
L’utilità (e il limite) di un sistema di pubblicazione automatizzato è quello di definire un modello, per esempio, per tutti gli articoli. In tale modello si indica dove verranno visualizzati, per esempio, il titolo, il testo, i link di navigazione... dell’articolo, e il sistema di pubblicazione creerà ogni singola pagina di articolo mettendo automaticamente questi elementi estratti dal database, con l’impaginazione concepita dal o dalla webmaster.
Quindi, questo sistema automatizzato permette una presentazione uniforme su tutto il sito... E questo è anche il suo limite: non è permesso definire un’interfaccia diversa per ogni singola pagina (si vedrà oltre che SPIP permette, al contrario, una certa flessibilità).
Quando si installa SPIP, viene proposto un set di modelli predefinito. Essi si trovano nella cartella dist/, alla radice del proprio sito. Se si desidera modificare questi file per adattarli ai propri bisogni oppure se si vuole installare un altro set di modelli, conviene creare una cartella chiamata squelettes/ allo stesso livello. Per ulteriori dettagli su tale argomento si legga l’articolo Dove mettere i file dei modelli?.
Quando un visitatore richiede la pagina http://esempio.org/spip.php?article3684, SPIP va a cercare un modello chiamato «article.html». Pertanto, SPIP si basa sull’indirizzo URL della pagina per determinare quale modello utilizzare:
| L’URL | chiamerà il modello |
|---|---|
spip.php?article3684 |
article.html |
spip.php?rubrique143 |
rubrique.html |
spip.php?mot12 |
mot.html |
spip.php?auteur5 |
auteur.html |
spip.php?site364 |
site.html |
Con due possibilità particolari:
- L’URL spip.php chiama il modello sommaire.html. Questo è la home page del sito.
- L’URL spip.php?page=abcd chiama il modello abcd.html. In altre parole, è possibile creare modelli che non sono previsti inizialmente dal sistema e di attribuire ad essi un nome di proprio gradimento.
Questa sintassi serve anche per le pagine quali la mappa del sito o i risultati di una ricerca, per esempio: spip.php?page=plan, spip.php?page=recherche&recherche=scoiattolo.
Quando SPIP chiama un modello gli passa un contesto
D’altronde, avete constatato che l’URL fornisce altri elementi in aggiunta al nome del modello. Per esempio, in spip.php?article3684, il numero dell’articolo richiesto (3684); in spip.php?page=recherche&recherche=scoiattolo, la parola cercata (scoiattolo).
Si tratta di un “contesto”, ovvero uno o più “variabili dipendenti da un contesto”, che SPIP fornisce al modello affinché queste possono essere utilizzate per comporre la pagina. In effetti, il modello article.html ha bisogno di conoscere il numero di articolo richiesto per cercarne il titolo, il testo e via dicendo nel database. Similmente, il modello recherche.html deve conoscere le parole cercate dal visitatore al fine di trovarle nel database che contiene questi termini.
In ogni URL, le variabili dipendenti dal contesto compaiono dopo il segno «?». Quando ve ne sono diverse esse sono separate da «&».
Nell’URL spip.php?page=recherche&recherche=scoiattolo, ci sono quindi due variabili: page e recherche, alle quali vengono attribuiti i valori rispettivamente di «recherche» e di «scoiattolo».
Nel caso di spip.php?article3684, SPIP ha semplificato l’URL che corrisponde in effetti a: spip.php?page=article&id_article=3684 (è proprio così, potete provare!). In questo esempio ci sono anche qui due variabili: page ha il valore "article" e id_article ha il valore "3684". Queste variabili permettono a SPIP di utilizzare i dati dell’articolo 3684 nel modello article.html.
Il principio di funzionamento della cache, in maniera semplificata
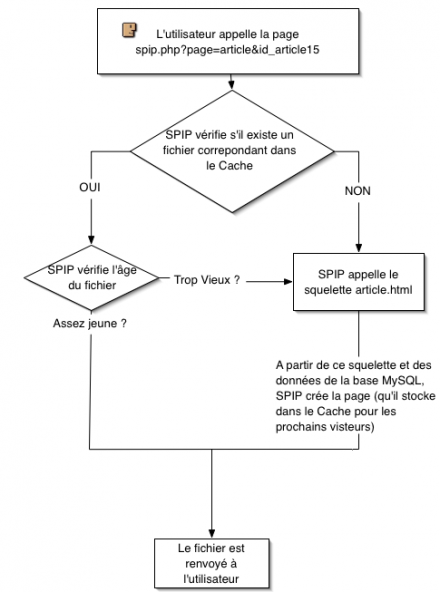
SPIP controlla se una pagina corrispondente all’URL richiesto si trova nella CACHE
- Se la pagina esiste, SPIP verifica che non sia troppo vecchia.
- Se la pagina è troppo vecchia, la ricalcola partendo dal modello e dal database MySQL. In seguito la registra nella CACHE, prima di inviarla all’utente che l’ha richiesta.
- Se la pagina è abbastanza recente, la invia all’utente.
- Se la pagina non esiste, la ricalcola partendo dal modello e dal database MySQL. In seguito la registra nella CACHE, prima di inviarla all’utente.
In occasione di una visita successiva, se l’intervallo di tempo tra le due visite è abbastanza breve, viene restituito la nuova pagina immagazzinata nella cartella /CACHE, senza dover generare nuovamente la pagina attingendo al database. In caso di blocco del database, la pagina contenuta nella cache viene inviata al visitatore in ogni caso, anche se è "troppo vecchia".
N.B. Da quanto suesposto si vede che ogni pagina del sito viene messa nella cache singolarmente, e ogni aggiornamento è provocato dalle visite del sito. Non c’è, in particolare, un aggiornamento di tutte le pagine del sito contemporaneamente e a scadenze fisse (questo tipo di "grandi manovre" ha il difetto di sovraccaricare il server e di farlo piantare, talvolta).
Come valore predefinito, una pagina viene considerata troppo vecchia dopo 3600 secondi. [1]
Il file .html
In SPIP i file .html vengono chiamati modelli. Sono questi che descrivono l’interfaccia grafica delle pagine.
Questi file sono redatti direttamente in HTML, al quale si aggiungono delle istruzioni che permettono di indicare a SPIP dove deve disporre gli elementi estratti dal database (del tipo: "metti il titolo qui", "qui indica l’elenco degli articoli riguardanti lo stesso argomento"...).
Le istruzioni per disporre gli elementi sono scritte in un linguaggio specifico, che è l’oggetto del presente manuale d’uso. Questo linguaggio è peraltro l’unica difficoltà di SPIP.
"Un altro linguaggio?" Be’ sì, è necessario imparare un nuovo linguaggio. Tuttavia, non è troppo complicato e permette di creare interfacce complesse molto rapidamente. In confronto alla coppia PHP/MySQL, noterete che vi farà guadagnare moltissimo tempo (soprattutto: è molto più semplice). È un markup language, cioè un linguaggio che utilizza dei marcatori simili a quelli dell’HTML.
N.B. Così come si impara l’HTML ispirandosi al codice sorgente dei siti che si visita, è possibile trarre ispirazione dai modelli utilizzati su altri siti che funzionano con SPIP. È sufficiente andare a cercare il file « .html » corrispondente. Per esempio, è possibile vedere il modello degli articoli di questo ciclo (visualizzare il codice sorgente per ottenere il testo del modello).
Un’interfaccia diversa nello stesso sito
In aggiunta all’impaginazione predefinita dei diversi contenuti del sito (rubrique.html, article.html, ecc.) è possibile creare dei modelli diversi per rubriche specifiche del sito e del loro contenuto. È sufficiente creare dei nuovi file .html e di attribuire loro un nome seguendo questi principi:
- Un’interfaccia diversa per una rubrica e quel che contiene (sotto-rubriche, articoli, brevi, ecc.): è necessario aggiungere al nome del file del modello corrispondente « -numero » (un trattino seguito da un numero di rubrica).
Per esempio, se si crea un file rubrique-60.html, esso verrà applicato alla rubrica n°60 e alle sue sotto-rubriche invece di utilizzare il file generico rubrique.html. Il modello article-60.html verrà applicato agli articoli della rubrica n°60. Se questa rubrica contiene delle sotto-rubriche, anche gli articoli contenuti in esse adotteranno il medesimo modello. Idem per breve-60.html... e così via.
- Un’interfaccia per un’unica rubrica. (SPIP 1.3) È possibile creare un’interfaccia che si applichi a una rubrica, ma non alle sue sotto-rubriche. Per fare ciò è necessario aggiungere al nome del file del modello corrispondente « =numero ».
Per esempio, è necessario creare un file rubrique=60.html, che verrà applicato unicamente alla rubrica n°60, ma non alle sue sotto-rubriche. Lo stesso vale per article=60.html, breve=60.html, ecc. Questi modelli si applicano al contenuto della rubrica n°60 ma i modelli delle sue sotto-rubriche adottano l’aspetto grafico predefinito.
N.B.: il numero indicato corrisponde a quello di una rubrica. I modelli article-60.html o article=60.html, quindi, non influenzeranno l’articolo n°60 ma tutti gli articoli contenuti nella rubrica n°60.
Cosa si può mettere in un file .html
I file .html sono essenzialmente dei file di "testo", completi di istruzioni per disporre gli elementi del database.
SPIP analizza unicamente le istruzioni di ubicazione degli elementi del database (codificati secondo il linguaggio specifico di SPIP); ignora completamente tutto quello che è nel file e che non corrisponde alle sue istruzioni.
Il loro contenuto essenziale è quindi in HTML. Si decide l’impaginazione, la versione dell’HTML desiderata, ecc. È possibile includere anche dei fogli di stile (CSS), oppure JavaScript, Flash... insomma: tutto quel che di solito si mette in una pagina Web.
Tuttavia è anche possibile (tutto è sempre e comunque solo testo) creare un XML (per esempio, « backend.html » generato dall’XML).
Ancora più originale: tutte le pagine inviate al visitatore sono estratte dalla CACHE da una pagina scritta in PHP. Possiamo includere nel nostro modello delle istruzioni in PHP, queste saranno eseguite durante la visita. Questa possibilità, se usata in maniera fine, permette una grande flessibilità a SPIP, che è possibile completare (per esempio aggiungendo un contatore, ecc.), oppure fare evolvere alcuni elementi di impaginazione in base alle informazioni estratte dal database.