Tot el contingut d’un lloc Web gestionat per SPIP està instal·lat en una base de dades MySQL. Per presentar aquestes dades als visitants del lloc necessita, per tant, realitzar una operació que consisteix en llegir les dades, organitzar-les i fer-ne la compaginació, per tal de mostrar una pàgina HTML al navegador Web.
En el cas de no emprar un gestor de continguts avançat com SPIP, aquesta operació és bastant complexa:
- cal conèixer la programació amb PHP i MySQL i escriure «rutines» relativament complexes;
- la integració d’aquestes rutines en una compaginació HTML elaborada és força difícil;
- cal desenvolupar tota una interfície per tal que els usuaris autoritzats puguin modificar el contingut de la base de dades;
- cal tenir en compte problemes d’execució: la crida sistemàtica del codi MySQL i PHP va consumint recursos, alenteix la visita i, en casos extrems, provoca bloquejos del del servidor Web.
SPIP proposa una solució completa per evitar aquestes dificultats:
- la compaginació del lloc s’efectua per mitjà de plantilles en format HTML anomenades esquelets que contenen instruccions simplificades que permeten indicar on i com es situen les dades tretes de la base de dades a la pàgina;
- un sistema de memòria cau permet emmagatzemar cada pàgina, evitant d’aquesta manera crides a la base de dades a cada visita. No només es redueix la càrrega al servidor, la velocitat d’accés a les pàgines augmenta, sinó que a més a més a més un lloc que funcioni sota SPIP es pot consultar encara que la base MySQL estiga parada;
- un «espai privat» que permet als administradors i redactors gestionar el conjunt de dades del lloc.
Per cada tipus de pàgina, un esquelet
L’interès (i la limitació) d’un sistema de publicació automatitzada és el de definir una plantilla, per exemple, per tots els articles. S’indica en aquesta plantilla (esquelet) on s’han de situar, per exemple, el títol, el text, els enllaços de navegació, ... de l’article i el sistema crearà cada pàgina individual d’article situant automàticament aquests elements extrets de la base de dades, en la compaginació que el/la administrador/a hagi concebut.
Aquest sistema automatitzat permet, per tant, una presentació coherent a l’interior d’un lloc... Però aquesta és també la seva limitació: no permet definir una interfície diferent per a cada pàgina aïllada (més tard veurem que SPIP permet tanmateix una certa flexibilitat).
Quan instal·leu SPIP, s’us proporciona un joc d’esquelets per defecte. Es troba a dins del directori dist/, a l’arrel del vostre lloc Web. Tan aviat com modifiqueu aquests fitxers per adaptar-los a les vostres necessitats, o bé si instal·leu algun altre joc d’esquelets, convé que creeu un directori anomenat squelettes/ al mateix nivell. Si voleu més detalls sobre aquesta qüestió, llegiu l’article: On ubicar els fitxers dels esquelets .
Quan un visitant demana la pàgina http://exemple.org/spip.php ?article3437, SPIP va a buscar un esquelet anomenat «article.html». SPIP es basa, per tant, amb l’adreça URL de la pàgina per determinar l’esquelet a emprar:
| L’URL | cridarà l’esquelet |
|---|---|
spip.php?article3437 |
article.html |
spip.php?rubrique143 |
rubrique.html |
spip.php?mot12 |
mot.html |
spip.php?auteur5 |
auteur.html |
spip.php?site364 |
site.html |
Amb dos casos especials:
- L’URL spip.php crida l’esquelt sommaire.html. Es tracta de la pàgina d’inici del lloc Web.
- L’URL spip.php?page=abcd crida l’esquelet abcd.html. En altres termes, podeu crear esquelets que no estiguin previstos pel sistema i anomenar-los com desitgeu.
Aquesta sintaxi serveix també, per exemple, per pàgines com el mapa del lloc o els resultats de recerca:
spip.php?page=plan, spip.php?page=recherche&recherche=esquirol.
Quan SPIP crida un esquelet, aquest li passa un context
D’altra banda, haureu constatat que l’URL ens proporciona altres elements a més del nom de l’esquelet. Per exemple, a spip.php?article3437, el número de l’article demanat (3437); a spip.php?page=recherche&recherche=esquirol, la paraula cercada (esquirol).
Es tracta d’un «entorn», és a dir, una o més «variables d’entorn», que SPIP proporcionarà a l’esquelet per tal que puguin ser utilitzades a l’hora de compaginar la pàgina. En efecte, l’esquelet article.html necessita conèixer el número de l’article demanat per trobar el seu títol, el seu text,... a la base de dades. De la mateixa manera, l’esquelet recherche.html ha de conèixer les paraules cercades pel visitant per tal de trobar els registres de la base de dades que contenen aquests termes.
En tota URL, les variables d’entorn apareixen després del «?». Quan n’hi ha moltes, estan separades per «&».
A l’URL, spip.php?page=recherche&recherche=esquirol,
hi ha dues variables: page i recherche, a les que se’ls atribueix els valors respectius «cerca» i «esquirol».
En el cas de spip.php?article3437, SPIP ha simplificat l’URL que correspon de fet a: spip.php?page=article&id_article=3437 (si si, podeu jugar-hi!). Tenim ací també dos valors: page té el valor "article" i id_article que té el valor "3437". Aquestes variables permeten a SPIP emprar les dades de l’article 3437 a dins de l’esquelet article.html.
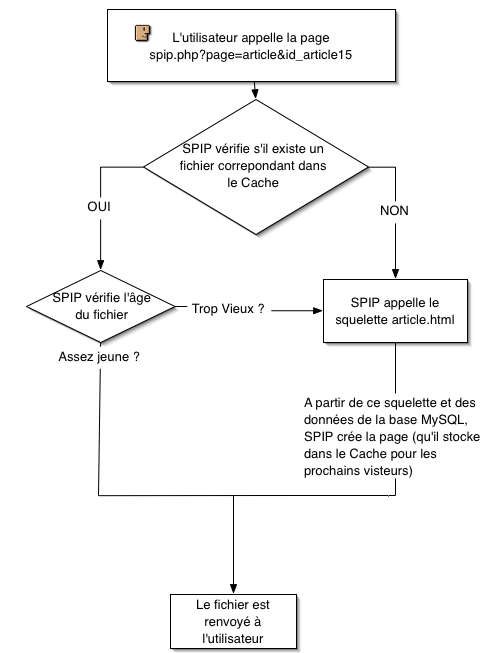
El principi de funcionament de la memòria cau, de manera simplificada

SPIP mira si una pàgina corresponent a l’URL demanada es troba a dins de la CACHE (memòria cau)
- Si la pàgina existeix, SPIP verifica que no sigui massa antiga.
- Si la pàgina és massa antiga, la torna a calcular a partir de l’esquelet i de la base MySQL. Després l’emmagatzema a dins de la CACHE, abans d’enviar-la a l’usuari.
- Si la pàgina és prou recent, la retorna a l’usuari.
- Si la pàgina no existeix, la calcula a partir del esquelet i de la base MySQL. Després l’emmagatzema a dins la CACHE, abans d’enviar-la a l’usuari.
En el transcurs de la següent visita, si el temps entre les dues visites és suficientment curt, serà aquesta nova pàgina emmagatzemada a /CACHE la que es mostrarà, sense necessitar fer un nou càlcul a partir de la base de dades. En cas de bloqueig de la base de dades, obligatòriament serà la pàgina que hi ha a la memòria cau la que es tornarà, fins i tot si és «massa antiga».
Nota. Veiem aquí que cada pàgina del lloc és emmagatzemada individualment a la memòria cau, i que cada recàrrega està provocada per les visites a la web. No hi ha en especial una recàrrega de totes les pàgines del lloc en un sol cop (aquest tipus de «grans manipulacions» tenen el mal gust de sobrecarregar el servidor i fins i tot, a vegades, el poden bloquejar).
Per defecte, una pàgina és considerada com a massa antiga al voltant dels 3600 segons. [1]
L’arxiu .html
A SPIP, anomenem als arxius .html com esquelets o plantilles. Aquests arxius són els encarregats de mostrar la interfície gràfica de les vostres pàgines.
Aquests arxius són redirigits directament en HTML, als que s’hi afegeixen instruccions que permeten indicar a SPIP on ha de situar els elements extrets de la base de dades (del tipus «situar el títol aquí», «indicar a aquest indret la llista dels articles que tracten el mateix tema,»...).
Les instruccions per situar els elements son escrites en un llenguatge de programació específic, que és el que es tracta d’explicar en aquest manual d’ús. Per altra banda, aquest llenguatge representa la única dificultat d’SPIP.
«Un altre llenguatge?» Doncs si, necessitareu aprendre un nou llenguatge. No obstant no és pas massa complicat, i permet crear interfícies complexes molt ràpidament. Pel que fa a la parella PHP/MsSQL, veureu que us farà guanyar un temps extraordinari (sobretot perquè és molt més simple). És un markup language, és a dir, un llenguatge que utilitza etiquetes similars a les del HTML.
Nota. De la mateixa manera que s’aprèn HTML inspirant-se en el codi font de les pàgines web que es visiten, podeu inspirar-vos en els esquelets utilitzats en altres llocs Web que funcionin amb SPIP. En tindreu prou anant a buscar l’arxiu «.html» corresponent. Per exemple, podeu veure l’esquelet dels articles d’aquest present cicle (visualitzeu el codi font per obtindre el text de l’esquelet).
Una interfície diferent a dins de la mateixa web
A més de la configuració de la pàgina per defecte de diferents continguts del lloc Web (rubrique.html, article.html, etc.), podeu crear diferents esquelets per seccions concretes del lloc i els seus continguts. N’hi ha prou creant nous fitxers .html i anomenant-los segons el següent principi:
- Una interfície diferent per una secció i els seus continguts (subseccions, articles, breus, etc.): fa falta completar el nom del fitxer esquelet corresponent per «-número» (un guionet seguit d’un número de secció).
Per exemple, si creeu un fitxer rubrique-60.html, s’aplicarà a la secció número 60 i a les seves subseccions en el lloc i situació de rubrique.html. L’esquelet article-60.html s’aplicarà als articles de la secció número 60. Si aquesta secció conté subseccions, els seus articles adoptaran igualment el nou esquelet. Passa el mateix amb breve-60.html... i així successivament.
- Una interfície per una única secció. (SPIP 1.3) Es pot crear una interfície que s’apliqui a una secció, però no a les seves subseccions. Per aconseguir-ho, fa falta completar el nom del fitxer esquelet corresponent per «=número».
Per exemple, s’ha de crear un fitxer rubrique=60.html, que s’aplicarà només a la secció número 60, per no a les seves subseccions. Igual per article=60.html, breve=60.html, etc. Aquests esquelets s’apliquen als continguts de la secció número 60 però els de les subseccions adopten l’aparença per defecte.
Fixeu-vos-hi bé: el número indicat és el d’una secció. Els esquelets article-60.html o article=60.html no fan referència a l’article número 60 sinó més aviat a tots els articles de la secció número 60.
Què es pot incloure en un fitxer .HTML
Els fitxers .html són essencialment arxius de «text», completats amb instruccions de situació dels elements de la base de dades.
SPIP analitza només les instruccions de situació dels elements de la base de dades (codificades segons el llenguatge específic d’SPIP) i es burla de tot allò que està situat a dins d’aquest fitxer i que no correspon a aquestes instruccions.
El seu contingut essencial és per tant l’HTML. Vosaltres determineu la presentació, la versió del HTML desitjat, etc. També hi podeu incloure, evidentment, fulls d’estil (CSS), però també JavaScript, Flash... a grans trets: tot allò que es pot posar habitualment en una pàgina Web.
També es pot crear, igualment, arxius XML (per exemple, «backend.html» generat del XML).
Més encara!: totes les pàgines retornades al visitant s’extreuen de la CACHE per una pàgina escrita en PHP. Podeu, per tant, incloure en els vostres esquelets instruccions en codi PHP ja que aquestes seran executades durant la visita. Emprada d’una manera acurada aquesta possibilitat aporta una gran flexibilitat a SPIP, permetent així completar-lo (per exemple afegint un comptador....) , o també presentar la pàgina web en funció de certes dades extretes de la base de dades.