La structure de la base de données est assez simple. Certaines conventions ont été utilisées, que vous repérerez assez facilement au cours de ce document. Par exemple, la plupart des objets sont indexés par un entier auto-incrémenté dont le nom est du type id_objet, et qui est déclaré comme clé primaire dans la table appropriée.
NB : cet article commençait à dater, et est en cours de mise à jour.
Contenu rédactionnel
Les rubriques : spip_rubriques
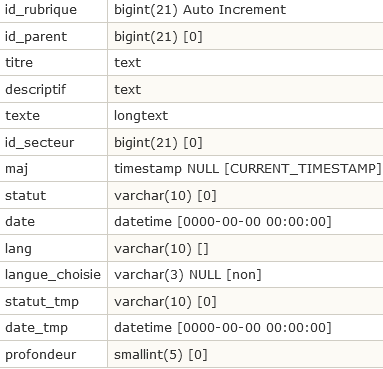
- Chaque rubrique est identifiée par son id_rubrique.
- id_parent est l’id_rubrique de la rubrique qui contient cette rubrique (zéro si la rubrique se trouve à la racine du site).
- titre, descriptif, texte parlent d’eux-mêmes.
- id_secteur est l’id_rubrique de la rubrique en tête de la hiérarchie contenant cette rubrique. Une rubrique dépend d’une rubrique qui dépend d’une rubrique... jusqu’à une rubrique placée à la racine du site ; c’est cette dernière rubrique qui détermine l’id_secteur. Cette valeur précalculée permet d’accélérer certains calculs de l’espace public (en effet, les brèves sont classées par secteur uniquement, et non selon toute la hiérarchie).
- maj est un champ technique mis à jour automatiquement par MySQL, qui contient la date de la dernière modification de l’entrée dans la table.
- statut
- date
- lang
- langue_choisie
- statut_tmp
- date_tmp
- profondeur
Les articles : spip_articles
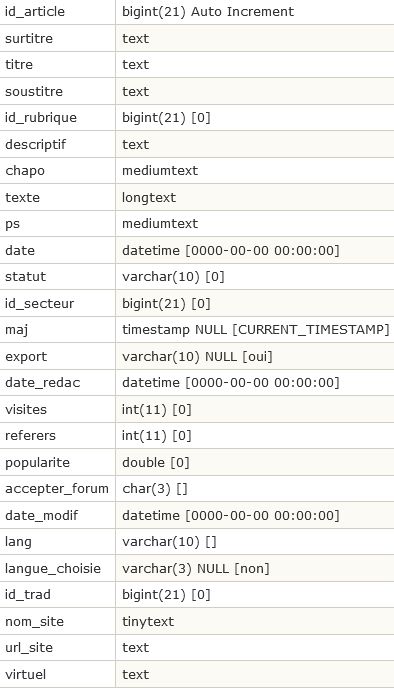
- Chaque article est identifié par son id_article.
- id_rubrique indique dans quelle rubrique est rangé l’article.
- id_secteur indique le secteur correspondant à la rubrique susmentionnée (voir le paragraphe précédent pour l’explication de la différence entre les deux).
- titre, surtitre, soustitre, descriptif, chapo, texte, ps parlent d’eux-mêmes.
- date est la date de publication de l’article (si l’article n’a pas encore été publié, c’est la date de création).
- date_redac est la date de publication antérieure si vous réglez cette valeur, sinon elle est égale à « 0000-00-00 ».
- statut est le statut actuel de l’article : prepa (en cours de rédaction), prop (proposé à la publication), publie (publié), refuse (refusé), poubelle (à la poubelle).
- accepter_forum : permet de régler manuellement si l’article accepte des forums (par défaut, oui).
- maj : même signification que dans la table des rubriques.
- export est un champ réservé pour des fonctionnalités futures.
- visites et referers sont utilisés pour les statistiques sur les articles. Le premier est le nombre de chargements de l’article dans l’espace public ; le deuxième contient un extrait de hash des différents referers, afin de connaître le nombre de referers distincts. Voir le plugin-dist statistiques.
- lang, langue_choise et id_trad permettent de gérer la langue des articles et les traductions
- nom_site, url_site
- virtuel : si l’option a été activée dans le contenu du site ce champ stocke les url des articles virtuels.
Les documents et images : spip_documents
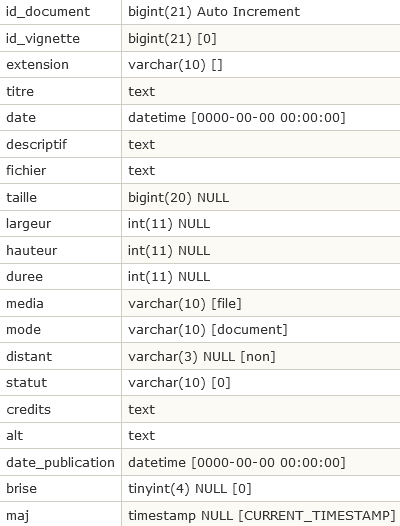
- id_document
- id_vignette id du document utilisé comme vignette si cette option est utilisée
- extension, le type de documents
- titre, descriptif, credits et alt données modifiables via l’interface
- date date d’ajout du document
- fichier est le nom du fichier
- taille, largeur, hauteur et duree informations récupérées sur le document si c’est une image ou une vidéo
- media peut être imageou file
- mode peut être logoon, logooff, image, document ou vignette
- distant copié d’un autre site
- statut propou publie
- date_publication date de publication du document
- brise
- maj même signification qu’ailleurs
Les auteurs : spip_auteurs
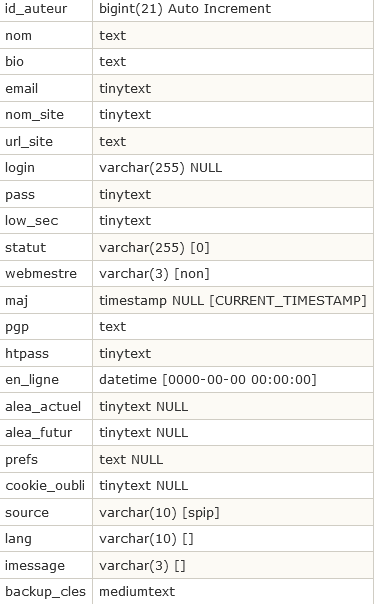
- Chaque auteur est identifié par son id_auteur.
- nom, bio, nom_site, url_site, pgp sont respectivement le nom de l’auteur, sa courte biographie, son adresse e-mail, le nom et l’URL de son site Web, sa clé PGP. Informations modifiables librement par l’auteur.
- email, login sont son e-mail d’inscription et son login. Ils ne sont modifiables que par un administrateur.
- pass est le hash MD5 du mot de passe.
- htpass est la valeur cryptée (i.e. générée par crypt()) du mot de passe pour le .htpasswd.
- low_sec
- statut est le statut de l’auteur : 0minirezo (administrateur), 1comite (rédacteur), 5poubelle (à la poubelle), 6forum (abonné aux forums, lorsque ceux-ci sont réglés en mode « par abonnement »).
- webmestre
- maj a la même signification que dans les autres tables.
- en_ligne
- alea_actuel
- alea_futur
- prefs
- cookie_oubli
- source
- lang
- imessage
- backup_cles
Les mots-clés : spip_mots
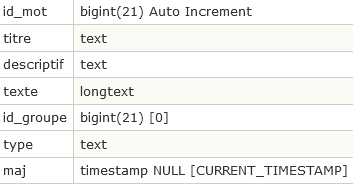
- Chaque mot-clé est identifié par son id_mot.
- Le type du mot-clé est le type, choisi pour le mot-clé. En définissant plusieurs types, on définit plusieurs classifications indépendantes (par exemple « sujet », « époque », « pays »...).
- id_groupe
- titre, descriptif, texte parlent d’eux-mêmes.
- maj : idem que dans les autres tables.
Les sites syndiqués : spip_syndic
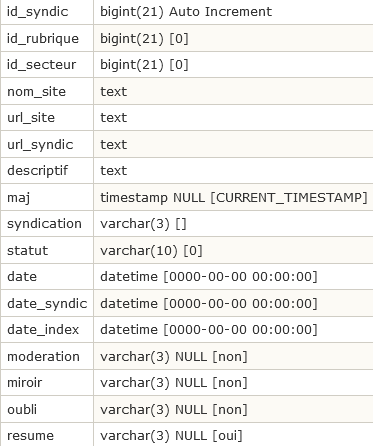
- Chaque site syndiqué est identifié par son id_syndic.
- id_rubrique et id_secteur définissent l’endroit dans la hiérarchie du site où viennent s’insérer les contenus syndiqués.
- nom_site, url_site, descriptif sont le nom, l’adresse et le descriptif du site syndiqué.
- url_syndic est l’adresse du fichier dynamique utilisé pour récupérer les contenus syndiqués (souvent il s’agit de url_site suivi de backend.php).
- syndication ouiou non la syndication est-elle active sur le site
- statut
- date
- date_syndic
- date_index
- moderation les contenus sont-ils modérés ou publiés avec un contrôle a posteriori
- miroir
- oubli les liens sont-ils effacés lorsqu’ils ne sont plus dans le fichier de syndication
- resume si oui on diffuse seulement un résumé de l’article syndiqué
Les articles syndiqués : spip_syndic_articles
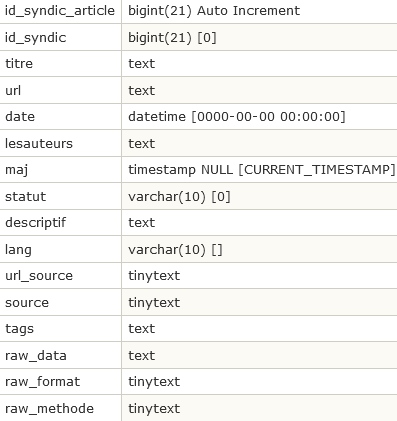
- Chaque article syndiqué est identifié par son id_syndic_article.
- id_syndic réfère au site syndiqué d’où est tiré l’article.
- titre, url, date, lesauteurs parlent d’eux-mêmes.
- maj
- statut
- descriptif
- lang
- url_source
- source
- tags
- raw_data
- raw_format
- raw_methode
Eléments interactifs
Les messages de forums : spip_forum
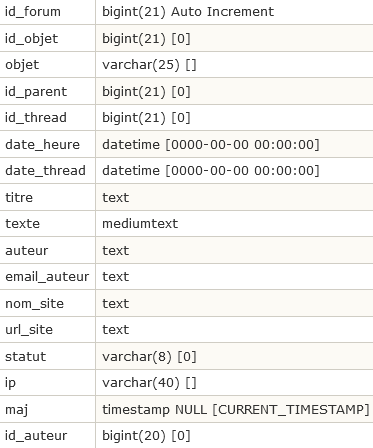
- Chaque message de forum est identifié par son id_forum.
- L’objet auquel est attaché le forum est identifié par son id_rubrique, id_article ou id_breve. Par défaut, ces valeurs sont égales à zéro.
- Le message parent (c’est-à-dire le message auquel répond ce message) est identifié par id_parent. Si le message ne répond à aucun autre message, cette valeur est égale à zéro.
- titre, texte, nom_site, url_site sont le titre et le texte du message,
le nom et l’adresse du lien y attaché.
- auteur et email_auteur sont le nom et l’e-mail déclarés par l’auteur. Dans le cas des forums par abonnement, ils ne sont pas forcément identiques aux données enregistrées dans la fiche de l’auteur (i.e. dans la table spip_auteurs).
- id_auteur identifie l’auteur du message dans le cas de forums par abonnement.
- statut est le statut du message. Les valeurs possibles sont décrites dans l’article La boucle FORUMS.
- ip est l’adresse IP de l’auteur, dans les forums publics.
- maj a la même signification que dans les autres tables.
Les relations entre objets

Ces tables ne gèrent aucun contenu, simplement une relation entre les objets présents dans d’autres tables. En standard SPIP livre quatre tables qui assurent les liens entre objets : spip_auteurs_liens, spip_documents_liens, spip_jobs_liens et spip_mots_liens
Ainsi :
- spip_auteurs_liens spécifie la relation entre auteurs et objets. Si un id_auteur y est associé à un id_article, cela veut dire que l’auteur en question a écrit ou co-écrit l’article (il peut y avoir plusieurs auteurs par article, et vice-versa bien sûr).
- spip_mots_liens définit de même la relation de référencement des articles par des mots-clés.
- spip_documents_liens (en exemple) définit la relation entre les documents et les différents objets éditorials.
Gestion du site
La table spip_meta est primordiale. Elle contient des couples (nom, valeur) indexés par le nom (clé primaire) ; ces couples permettent de stocker différentes informations telles que la configuration du site, ou la version installée de SPIP.
On y trouve également les informations sur les plugins installés ainsi que leurs paramétrages. Certaines de ces informations sont sérialisées, comme par exemple celles de la configuration de bigup.
