Tout le contenu d’un site géré sous SPIP est installé dans une base de données MySQL. Pour présenter ces informations aux visiteurs du site, il faut donc réaliser l’opération qui consiste à lire les informations, à les organiser et à les mettre en page, afin d’afficher une page HTML dans le navigateur Web.
A moins d’utiliser un gestionnaire de contenu avancé comme SPIP, cette opération est assez fastidieuse :
- il faut connaître la programmation PHP et MySQL, et écrire des « routines » relativement complexes ;
- l’intégration de telles routines dans une mise en page HTML élaborée est assez pénible ;
- il faut développer toute une interface pour que les utilisateurs autorisés modifient le contenu de la base de données ;
- il faut prendre en compte des problèmes de performances : le recours systématique à du code MySQL et PHP est gourmand en ressources, ralentit la visite et, dans des cas extrêmes, provoque des plantages du serveur Web.
SPIP propose une solution complète pour contourner ces difficultés :
- la mise en page du site est effectuée au moyen de gabarits au format HTML nommés squelettes, contenant des instructions simplifiées permettant d’indiquer où et comment se placent les informations tirées de la base de données dans la page ;
- un système de cache permet de stocker chaque page et ainsi d’éviter de provoquer des appels à la base de données à chaque visite. Non seulement la charge sur le serveur est réduite, la vitesse très largement accélérée, de plus un site sous SPIP reste consultable même lorsque la base MySQL est plantée ;
- un « espace privé » permettant aux administrateurs et aux rédacteurs de gérer l’ensemble des données du site.
Pour chaque type de page, un squelette
L’intérêt (et la limite) d’un système de publication automatisé, est de définir un gabarit pour, par exemple, tous les articles. On indique dans ce gabarit (le squelette) où viendront se placer, par exemple, le titre, le texte, les liens de navigation... de l’article, et le système fabriquera chaque page individuelle d’article en plaçant automatiquement ces éléments tirés de la base de données, dans la mise en page conçue par la/le webmestre.
Ce système automatisé permet donc une présentation cohérente à l’intérieur d’un site... Et c’est aussi sa limite : il ne permet pas de définir une interface différente pour chaque page isolée (on verra plus loin que SPIP autorise cependant une certaine souplesse).
Lorsque vous installez SPIP, un jeu de squelettes est proposé par défaut. Il se trouve dans le répertoire squelettes-dist/, à la racine de votre site. Dès que vous modifiez ces fichiers pour les adapter à vos besoins, ou si vous voulez installer un autre jeu de squelettes, il convient de créer un répertoire nommé squelettes/ au même niveau. Pour plus de détails sur cette question, lire l’article Où placer ses squelettes .
Lorsqu’un visiteur demande la page http://exemple.org/spip.php?article3437, SPIP va chercher un squelette nommé « article.html ». SPIP se base donc sur l’adresse URL de la page pour déterminer le squelette à utiliser :
| L’URL | appellera le squelette |
|---|---|
spip.php?article3437 |
article.html |
spip.php?rubrique143 |
rubrique.html |
spip.php?mot12 |
mot.html |
spip.php?auteur5 |
auteur.html |
spip.php?site364 |
site.html |
Avec deux cas particuliers :
- L’URL spip.php appelle le squelette sommaire.html. Il s’agit de la page d’accueil du site.
- L’URL spip.php?page=abcd appelle le squelette abcd.html. En d’autres termes, vous pouvez créer des squelettes qui ne sont pas prévus par le système et les nommer comme vous le souhaitez.
Cette syntaxe sert également pour les pages telles que le plan du site ou les résultats de recherche par exemple : spip.php?page=plan, spip.php?page=recherche&recherche=ecureuil.
Lorsque SPIP appelle un squelette, il lui passe un contexte
Par ailleurs, vous aurez constaté que l’URL fournit d’autres éléments que le nom du squelette. Par exemple, dans spip.php?article3437, le numéro de l’article demandé (3437) ; dans spip.php?page=recherche&recherche=ecureuil, le mot recherché (ecureuil).
Il s’agit d’un « contexte », c’est-à-dire, une ou plusieurs « variables d’environnement », que SPIP va fournir au squelette pour qu’elles puissent être utilisées dans la composition de la page. En effet, le squelette article.html a besoin de connaître le numéro de l’article demandé pour rechercher son titre, son texte,... dans la base de données. De même, le squelette recherche.html doit connaitre les mots recherchés par le visiteur pour trouver les enregistrements de la base de données qui contiennent ces termes.
Dans toute URL, les variables d’environnement apparaissent après le « ? ». Lorsqu’il y en a plusieurs, elles sont séparées par des « & ».
Dans l’URL spip.php?page=recherche&recherche=ecureuil, on a donc deux variables : page et recherche, auxquelles on attribue les valeurs respectives « recherche » et « écureuil ».
Dans le cas de spip.php?article3437, SPIP a simplifié l’URL qui correspond en fait à : spip.php?page=article&id_article=3437 (si si, vous pouvez essayer !). On a donc ici aussi deux variables : page a la valeur "article" et id_article a la valeur "3437". Ces variables permettent à SPIP d’utiliser les données de l’article 3437 dans le squelette article.html.
Le principe de fonctionnement du cache, de manière simplifiée
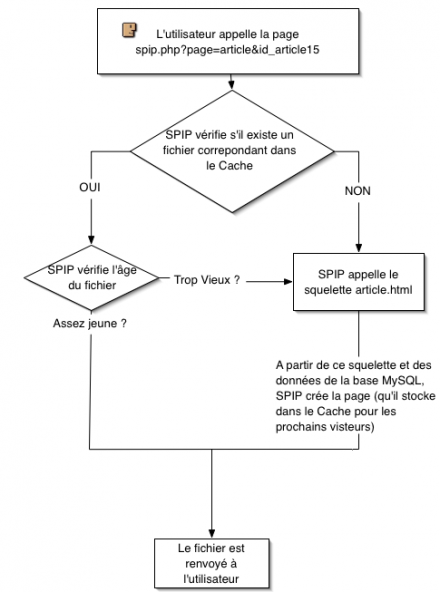
SPIP regarde si une page correspondante à l’URL demandée se situe dans le CACHE
- Si la page existe, SPIP vérifie qu’elle n’est pas trop ancienne.
- Si la page est trop ancienne, SPIP la recalcule à partir du squelette et de la base MySQL, puis la stocke dans le CACHE, avant de l’envoyer à l’utilisateur.
- Si la page est assez récente, SPIP la retourne à l’utilisateur.
- Si la page n’existe pas, SPIP la calcule à partir du squelette et de la base MySQL, puis la stocke dans le CACHE, avant de l’envoyer à l’utilisateur.
Lors d’une visite suivante, si le délai entre les deux visites est suffisamment court, c’est donc cette nouvelle page stockée dans /tmp/cache qui est retournée, sans avoir à faire un nouveau calcul à partir de la base de données. En cas de plantage de la base de données, c’est forcément la page en cache qui est retournée, même si elle est « trop âgée ».
Remarque. On voit ici que chaque page du site est mise en cache individuellement, et chaque recalcul est provoqué par les visites du site. Il n’y a pas, en particulier, un recalcul de toutes les pages du site d’un seul coup à échéance régulière (ce genre de « grosse manœuvres » ayant le bon goût de surcharger le serveur et de le faire parfois planter).
Par défaut, si aucune balise #CACHE n’est utilisée en début de squelette, une page est considérée comme trop vieille au bout de 24 heures. [1]
Le fichier .html
Dans SPIP, nous appelons les fichiers .html les squelettes. Ce sont eux qui décrivent l’interface graphique de vos pages.
Ces fichiers sont rédigés directement en HTML, auquel on ajoute des instructions permettant d’indiquer à SPIP où il devra placer les éléments tirés de la base de données (du genre : « placer le titre ici », « indiquer à cet endroit la liste des articles portant sur le même thème »...).
Les instructions de placement des éléments sont rédigées dans un langage spécifique, qui fait l’objet du présent manuel d’utilisation. Ce langage constitue par ailleurs la seule difficulté de SPIP.
« Encore un langage ? » Hé oui, il va vous falloir apprendre un nouveau langage. Il n’est cependant pas très compliqué, et il permet de créer des interfaces complexes très rapidement. Par rapport au couple PHP/MySQL, vous verrez qu’il vous fait gagner un temps fou (surtout : il est beaucoup plus simple). C’est un markup language, c’est-à-dire un langage utilisant des balises similaires à celles du HTML.
Que peut-on mettre dans un fichier .html
Les fichiers .html sont essentiellement des fichiers « texte », complétés d’instructions de placement des éléments de la base de données.
SPIP analyse uniquement les instructions de placement des éléments de la base de données (codées selon le langage spécifique de SPIP) ; il se contrefiche de ce qui est placé dans ce fichier et qui ne correspond pas à ces instructions.
Leur contenu essentiel est donc du HTML. Vous déterminez la mise en page, la version du HTML désiré, etc. Vous pouvez évidemment y inclure des feuilles de style (CSS), mais également du JavaScript, du Flash... en gros : tout ce qu’on place habituellement dans une page Web.
Mais vous pouvez également (tout cela n’est jamais que du texte) créer du XML (par exemple, « backend.html » génère du XML).
Plus original : toutes les pages retournées au visiteur sont tirées du CACHE par une page écrite en PHP. Vous pouvez donc inclure dans vos squelettes des instructions en PHP, elles seront exécutées lors de la visite. Utilisée de manière assez fine, cette possibilité apporte une grande souplesse à SPIP, que vous pouvez ainsi compléter (par exemple ajouter un compteur, etc.), ou même faire évoluer certains éléments de mise en page en fonction des informations tirées de la base de données.