De volledige inhoud van een met SPIP beheerde site staat opgeslagen in een MySQL database. Om die inhoud aan de bezoekers van de site te kunnen presenteren, moet die inhoud worden uitgelezen, worden geörganiseerd en als een pagina opgebouwd met HTML in een webbrowser worden weergegeven.
Zonder geavanceerd beheersysteem als SPIP is dit geen eenvoudige klus:
- je moet kunnen programmeren in PHP en MySQL, en relatief ingewikkelde «routines» kunnen schrijven;
- de integratie van deze routines in een HTML-pagina is een ingewikkelde zaak;
- je moet een interface ontwikkelen waarmee een gebruiker met de juiste toegangsrechten de inhoud van de database kan bewerken;
- je moet rekening houden met prestatieproblemen; systematisch je toevlucht nemen tot MySQL en PHP vereist veel resources, vertraagt de responsetijd en kan soms zelfs tot het vastlopen van de webserver leiden.
SPIP beidt een complete oplossing om deze problemen te overwinnen:
- het in een webpagina omzetten gebeurt aan de hand van modellen in HTML formaat die skeletten (squelettes) worden genoemd en eenvoudige instructies bevatten waarmee kan worden aangegeven waar wat en hoe de informatie uit de database moet worden weergegeven;
- een cache slaat iedere pagina op en voorkomt dat de database iedere keer opnieuw moet worden aangesproken. Niet alleen de serverbelasting vermindert, maar ook de responstijd en zelfs als de verbinding met de database is onderbroken, kunnen de pagina’s worden opgevraagd;
- een «privé gedeelte» biedt beheerders en auteurs een interface om de inhoud van de site te beheren.
Elk type pagina heeft zijn skelet
Het belang (en de beperking) van een geautomatiseerd publicatiesysteem is het definiëren van een sjabloon voor bijvoorbeeld alle artikelen. In dit sjabloon (wat in SPIP een skelet wordt genoemd) geven we aan waar bijvoorbeeld de titel en de tekst moeten komen staan, hoe de navigatie eruit moet zien en hoe we het logo van de site willen tonen. Het systeem gaat vervolgens voor ieder artikel die gegevens uit de database halen en in HTML-formaat op de door de webmaster aangegeven manier in een webpagina plaatsen.
Het systeem biedt dus een coherente presentatie, en dat is direct ook de beperking... Je kunt niet voor iedere afzonderlijke pagina een aparte weergave definiëren (hoewel je later zult zien dat er toch wel wat souplesse in SPIP zit).
Wanneer je SPIP installeert, krijg je de beschikking over een standaard set van skeletten. Ze staan in een map squelettes-dist/, in de root van de site. Je kunt die skeletten aan jouw wensen aanpassen, of een andere set skeletten installeren. Je doet dat niet in de standaard map, maar je maakt een eigen map squelettes/ op hetzelfde niveau. Je kunt er een uitgebreide uitleg over vinden in artikel Waar plaats ik mijn aangepaste skeletten?
Wanneer een bezoeker van de site een pagina op vraagt, bijvoorbeeld via een link http://mijnsite.nl/spip.php?article3437, gaat SPIP zoeken naar een skelet «article.html». SPIP baseert zich dus op het URL adres om te bepalen welk skelet moet worden gebruikt:
| URL | opgeroepen skelet |
|---|---|
spip.php?article3437 |
article.html |
spip.php?rubrique143 |
rubrique.html |
spip.php?mot12 |
mot.html |
spip.php?auteur5 |
auteur.html |
spip.php?site364 |
site.html |
Er zijn twee uitzonderingen:
- de URL spip.php roept het skelet sommaire.html op, de beginpagina van de site;
- de URL spip.php?page=abcd roept een skelet abcd.html op. Hiermee kun je dus je zelfgemaakte skeletten aanroepen voor onderdelen die in het standaardsysteem niet zijn opgenomen.
Deze laatste syntax wordt ook toegepast op enkele standaardpagina’s, zoals de sitemap: spip.php?page=plan, of de pagina voor zoekresultaten spip.php?page=recherche&recherche=zoekterm.
Wanneer SPIP een skelet oproept, geeft het een context mee
Het is niet alleen het skelet wat door de URL wordt aangegeven. In spip.php?article3437 Vindt SPIP ook het nummer van het artikel (3437) terug en in spip.php?page=recherche&recherche=zoekterm staat het gezochte woord (zoekterm).
We noemen dit de «context», één of meerdere «omgevingsvariabelen» die SPIP aanlevert aan het skelet om de pagina op te kunnen bouwen. Het skelet article.html moet immers het artikelnummer kennen om zo de juiste gegevens te kunnen weergeven.
In de URL verschijnen deze omgevingsvariabelen achter «?» en zijn het er meer, dan worden ze gescheiden door een «&».
In de URL spip.php?page=recherche&recherche=zoekterm staan dus twee variabelen: page en recherche met hun rspectievelijke waardes «recherche» en «zoekterm».
In het geval van spip.php?article3437 gebruikt SPIP een vereenvoudigde syntax, want in feite staat er: spip.php?page=article&id_article=3437 (wat net zo goed zal werken!). Ook hier dus twee variabelen: page met waarde "article" en id_article met waarde "3437". Deze variabelen laten SPIP dus toe in het skelet article.html de gegevens van artikel 3437 op te vragen.
Een simpele uitleg van de cache
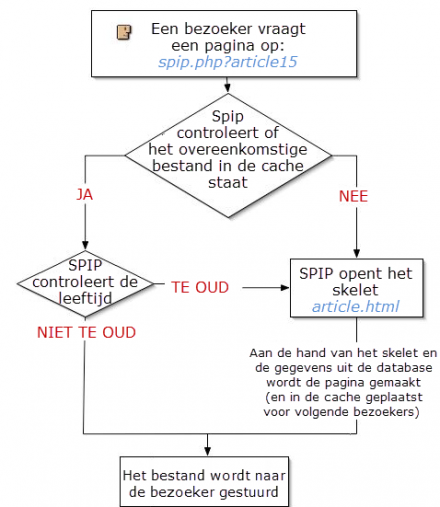
Voor SPIP een pagina opbouwt, kijkt het of die pagina misschien al staat opgeslagen in de CACHE
- Vindt SPIP de pagina, dan controleert het of die pagina niet verouderd is.
- Is de pagina te oud, dan wordt hij herberekend aan de hand van het skelet en de MySQL database, en vervolgens in de CACHE opgeslagen, waarna hij naar de gebruiker wordt gestuurd.
- Is de pagina recent genoeg, dan wordt de pagina vanuit de cache naar de gebruiker gestuurd.
- Bestaat de pagina niet, dan zal SPIP hem aan de hand van het skelet en de MySQL database berekenen, in de CACHE opslaan en hem daarna naar de gebruiker opsturen.
Bij een volgend bezoek na een niet te lange tussenduur wordt dus een in de map /tmp/cache opgeslagen pagina geretourneerd, zonder dat een herberekening plaats vindt. En mocht er een probleem zijn met de database, dan wordt de pagina altijd uit de cache doorgestuurd, zelfs als deze «te oud» mocht zijn.
Opmerking: Je ziet dat iedere pagina individueel in de cache wordt geplaatst. Er vindt geen herberekening plaats van alle pagina’s van de site, wat ook een overbelasting van de webserver zou kunnen veroorzaken!
In een skelet geeft een baken #CACHE aan hoe oud een pagina mag zijn voor hij moet worden herberekend. Ontbreekt dit baken, dan wordt een levensduur van 24 uur aangehouden. [1]
Het .html bestand
In SPIP worden de .html bestanden skeletten genoemd. Zij bepalen de grafische interface van je webpagina’s.
Deze bestanden worden opgebouwd in HTML, waaraan de markuptaal van SPIP wordt toegevoegd om aan te geven waar en hoe de gegevens uit de database moeten worden geplaatst (in de vorm: «plaats de titel hier», «toon hier een lijst artikelen met hetzelfde thema»...).
Deze instructies worden in een specifieke taal geschreven, waarover je in deze documentatie leest. Net als iedere taal moet je hem aanleren. Een beetje kennis van de Franse taal kan daarbij handig zijn, maar is niet noodzakelijk.
«Nog een taal?» Ja, je moet een nieuwe programmeertaal leren. Ze is niet erg gecompliceerd en je kunt er snel resultaat mee boeken. Vergeleken bij PHP en MySQL, ga je heel veel tijdswinst boeken (want de taal van SPIP is heel wat simpeler). Net als HTML is het een markuptaal die gebruikt maakt van tags, die we in deze documentatie "bakens" noemen om ze te onderscheiden van de HTML-tags.
Opmerking: Op dezelfde manier als dat je jezelf HTML kunt aanleren door naar de broncode van andere sites te kijken, kun je dat ook doen met de «.html» bestanden van SPIP. Je kunt bijvoorbeeld kijken naar het skelet van dit artikel (bekijk vervolgens de broncode om de volledige inhoudvan het skelet te bekijken). Onderaan iedere bladzijde in deze documentatie zie je ook een link naar het skelet!
Meerdere layouts binnen dezelfde site
Naast een standaardweergave voor de verschillende objecten van de site (rubrieken, artikelen, enz.), kun je per rubriek een andere layout kiezen voor de inhoud (artikelen, nieuwsberichten, subrubrieken, enz.). Je leest hierover in het artikel Varianten van skeletten.
Wat kun je in een .html bestand opnemen
De .html bestanden zijn feitelijk tekstbestanden, aangevuld met instructies waarmee gegevens uit de database worden onttrokken.
SPIP analyseert uitsluitend de instructies die bedoeld zijn om gegevens uit de database weer te geven (gecodeerd met de markuptaal SPIP); dat wordt in de tekst opgenomen, samen met alles wat SPIP niet herkende.
Hun wezenlijke inhoud is dus HTML. Je bepaalt er de layout mee, maas ook de HTML-versie die je wilt gebruiken, enz. Je kunt er natuurlijk stylesheets aan toevoegen, maar ook bijvoorbeeld JavaScript... alles wat normaalgesproken op een webpagina wordt geplaatst.
Je kunt ook XML bestanden maken (zoals «backend.html», de RSS-feed van SPIP).
Alle aan de bezoekers gezonden pagina’s komen uit een in PHP geschreven pagina in de CACHE. Je kunt dus in je skeletten PHP-instructies schrijven, die bij iedere opvraging worden uitgevoerd. Dit verhoogt de functionaliteit van SPIP. Zo kan je bijvoorbeeld een teller toevoegen, of zelfs bepaalde elementen laten evolueren aan de hand van gegevens uit de database.