Todo el contenido de un sitio gestionado por SPIP está instalado en una base de datos MySQL. Para presentar estos datos a los visitantes del sitio es necesario, por tanto, realizar una operación que consiste en leer los datos, organizarlos y componerlos, para mostrar una página HTML al navegador web.
Si no se utiliza un gestor de contenidos avanzado como SPIP, esta operación es bastante compleja:
- hay que saber programar con PHP y MySQL y escribir código relativamente complejo;
- la inserción de este código en una plantilla HTML elaborada es muy difícil;
- hay que desarrollar toda una interfaz para que los usuarios autorizados puedan modificar el contenido de la base de datos;
- hay que tener en cuenta los problemas de rendimiento: la llamada sistemática a código MySQL y PHP consume recursos, ralentizando la visualización de la página, y provocando en casos extremos la caída del servidor web.
SPIP propone una solución completa para evitar estas dificultades:
- la presentación de las páginas del sitio se efectúa mediante plantillas en formato HTML llamadas esqueletos que contienen instrucciones simplificadas que permiten indicar dónde y cómo se sitúan los datos sacados de la base de datos en la página;
- un sistema de memoria caché permite almacenar cada página, evitando así llamadas a la base de datos en cada visita. No sólo se reduce la carga del servidor y la velocidad de acceso a las páginas aumenta, sino que además, un sitio SPIP se puede consultar aunque la base de datos MySQL esté parada;
- un «espacio privado» permite que los administradores y redactores gestionen el conjunto de datos del sitio.
Para cada tipo de página, un esqueleto
El interés (y la limitación) de un sistema de publicación automatizada consiste en definir una plantilla, por ejemplo, para todos los artículos. En esta plantilla (esqueleto) se indica dónde se han de situar, por ejemplo, el título, el texto, los enlaces de navegación... del artículo y el sistema creará cada artículo en su página individual situando automáticamente estos elementos extraídos de la base de datos, con la composición que la webmistress haya decidido.
Este sistema automático permite, por tanto, una presentación coherente al interior del sitio... Pero esta es también su limitación: no permite definir una interfaz diferente para cada página de forma aislada (más tarde veremos que SPIP permite no obstante una cierta flexibilidad).
Cuando instalas SPIP, se te proporciona un juego de esqueletos por omisión. Estos esqueletos se encuentran en el directorio dist/, en la raíz de tu sitio web. Tan pronto como modifiques estos ficheros para adaptarlos a tus necesidades, o si quieres instalar un nuevo juego de esqueletos, conviene crear un nuevo directorio llamado squelettes/ al mismo nivel. Para más detalles sobre esta cuestión, puedes consultar el artículo ¿Dónde poner los archivos de esqueletos?.
Cuando un visitante solicita la página http://ejemplo.org/spip.php?article3437, SPIP busca un esqueleto llamado «article.html». SPIP se basa, por tanto, en la dirección URL de la página para determinar el esqueleto a usar:
| La URL | llamará al esqueleto |
|---|---|
spip.php?article3437 |
article.html |
spip.php?rubrique143 |
rubrique.html |
spip.php?mot12 |
mot.html |
spip.php?auteur5 |
auteur.html |
spip.php?site364 |
site.html |
Con dos casos especiales:
- La URL spip.php llama al esqueleto sommaire.html. Se trata de la página de inicio del sitio.
- La URL spip.php?page=abcd llama al esqueleto abcd.html. Es decir, puedes crear nuevos esqueletos que no estén previstos por el sistema SPIP y llamarlos como quieras.
Esta sintaxis sirve igualmente, por ejemplo, para páginas como el mapa del sitio o la de los resultados de una búsqueda: spip.php?page=plan, spip.php?page=recherche&recherche=ardilla.
Cuando SPIP llama a un esqueleto, le pasa el contexto
Por otro lado, habrás constatado que la URL nos proporciona otros elementos además del nombre del esqueleto. Por ejemplo, en spip.php?article3437, el número del artículo solicitado (3437); en la URL spip.php?page=recherche&recherche=ardilla, la palabra buscada (ardilla).
Se trata de un «contexto», es decir, una o más «variables de entorno», que SPIP proporcionará al esqueleto para que puedan ser utilizadas en el momento de componer la página. En efecto, el esqueleto article.html necesita conocer el número del artículo solicitado para encontrar su título, su texto... dentro de la base de datos. De la misma forma, el esqueleto recherche.html ha de conocer las palabras buscadas por el visitante para encontrar los registros de la base de datos que contienen estos términos.
En toda URL, las variables de entorno aparecen después de un interrogante «?». Cuando hay varias variables, se separan con «&».
En la URL spip.php?page=recherche&recherche=ardilla hay dos variables: page y recherche, a las que se atribuyen los respectivos valores «recherche» y «ardilla».
En el caso de spip.php?article3437, SPIP ha simplificado la URL que le corresponde a spip.php?page=article&id_article=3437 (¡sí, puedes comprobarlo!). Tenemos aquí también dos valores: page con el valor «article» e id_article con el valor «3437». Estas variables permiten que SPIP utilice los datos del artículo 3437 en el esqueleto article.html.
El principio de funcionamiento de la memoria caché, de manera simplificada
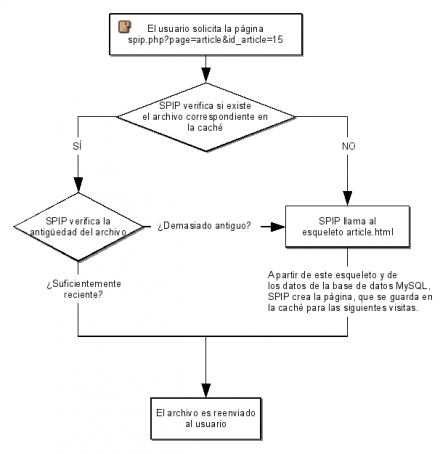
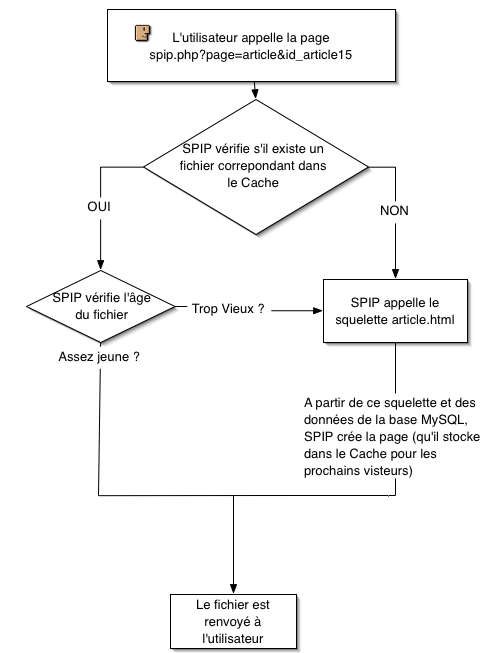
SPIP mira si una página correspondiente a la URL solicitada está situada en la memoria caché.
- Si existe, SPIP verifica que no sea demasiado antigua.
- Si la página es demasiado antigua, la recarga a partir del esqueleto y la base de datos MySQL. Después la vuelve a almacenar dentro de la caché, antes de enviarla al usuario/visitante.
- Si la página es suficientemente reciente, la muestra al usuario.
- Si la página no existe, la crea a partir del esqueleto y la base de datos MySQL. Después la almacena en la caché, antes de enviarla al usuario/visitante.
En el transcurso de la siguiente visita, si el tiempo entre ambas visitas es suficientemente corto, será esta nueva página almacenada en /CACHE, el directorio de la caché, la que se mostrará, sin necesidad de hacer un nuevo cálculo a partir de la base de datos. En caso de bloqueo de la base de datos, se enviará obligatoriamente la página que está en la caché, incluso aunque sea demasiado antigua.
Nota. Aquí vemos que cada página del sitio se almacena individualmente en la caché, y que cada recarga es provocada por las visitas a la web. No hay, en especial, una recarga de todas las páginas del sitio de una sola vez a intervalos regulares (este tipo de «grandes manipulaciones» tienen el mal gusto de sobrecargar el servidor, y a veces, incluso, lo pueden bloquear).
Por defecto, una página se considera «muy antigua» cuando tiene alrededor de 3600 segundos. [1]
El archivo .html
En SPIP llamamos plantillas o esqueletos a los archivos .html. Estos archivos son los encargados de mostrar la interfaz gráfica de las páginas.
Estos archivos son redactados directamente en HTML, al que se le añaden instrucciones que permiten indicar a SPIP dónde ha de situar los elementos extraídos de la base de datos (del tipo «situar el título aquí», «indicar en este lugar la lista de artículos que tratan del mismo tema»...).
Las instrucciones para situar los elementos están escritas en un lenguaje de programación específico, que es el que se trata de explicar en este manual de uso. Por otro lado, este lenguaje representa la única dificultad de SPIP.
«¿Otro lenguaje?» Pues sí, tendrás que aprender un nuevo lenguaje. No obstante, no es muy complicado y permite crear interfaces complejas muy rápidamente. Comparado con la pareja PHP/MySQL, verás que te hará ganar muchísimo tiempo (sobre todo porque es mucho más simple). Es un markup language (lenguaje de marcas), es decir, un lenguaje que utiliza etiquetas similares a las que tiene HTML.
Qué se puede incluir en un archivo .html
Los archivos .html son esencialmente ficheros de «texto», con instrucciones que sitúan los elementos de la base de datos.
SPIP analiza únicamente las instrucciones de situación de los elementos de la base de datos (codificadas con el lenguaje propio de SPIP) y se desentiende de todo aquello que está dentro de este archivo y no corresponde a estas instrucciones.
Su contenido esencial es, por tanto, código HTML. Tú determinarás la presentación, la versión de HTML deseada, etc. Evidentemente, puedes incluir hojas de estilo (CSS), pero también JavaScript, Flash... en fin, todo aquello que podría ser incluido habitualmente en una página web.
También se pueden crear igualmente, pues no es otra cosa que texto, archivos XML (por ejemplo, «backend.html» generado en XML).
Más todavía: todas las páginas devueltas al visitante se extraen de la caché mediante una página escrita en PHP. Puedes, por tanto, incluir instrucciones en código PHP en tus esqueletos, ya que éstas serán ejecutadas durante la visita. Utilizada de forma cuidadosa, esta posibilidad aporta una gran flexibilidad a SPIP, y permite completarlo (por ejemplo, añadiendo un contador...), o presentar igualmente la página web en función de ciertos datos extraídos de la base de datos.