All of the content for a site managed with SPIP is stored in a MySQL database. In order to present these data to visitors of the site, it is then necessary to execute an operation which consists of reading those data, organising them, formatting them, and finally displaying an HTML page within a Web browser.
Unless using an advanced content management system like SPIP, such operations can be quite unwieldy:
- you need to know how to programme in PHP and MySQL, and to code "routines" that are relatively complex;
- you must integrate these routines with complex HTML page formatting that is temperamental at best;
- you need to develop an interface so that authorised users can modify the contents in the database;
- you need to take account of performance issues: constantly using PHP and MySQL code consumes a lot of system resources, slows down visits to the site, and in extreme cases, can make your web server actually crash.
SPIP offers a complete solution to overcome these difficulties and more:
- formatting for the site is accomplished using HTML-formatted template files known as squelettes (French for skeletons), which contain simplified instructions indicating where and how to position the data extracted from the database on to the HTML page;
- a cache system used to store every page and thereby avoid making so many calls to the database for every site visitor. This not only reduces the load on the server, but response time is much quicker, and the site remains visible even if the MySQL database for the site actually crashes;
- a "private zone" that is used by administrators and editors to manage all the data used for the site.
One basic template file for each type of page
A key benefit and limitation of an automated publishing system is defining a template file that can, for instance, be used for publishing all of the articles for a site. Indicated in this template is information on where to position the title, the text, the navigation links, etc. for the article, and we then allow the system to generate each individual article’s page by automatically positioning the corresponding data from the database into the correct positions as intended by the webmaster.
This automated system then enables a consistent presentation across the site... and this also constitutes a limitation: it is unable to define a different interface for every single page (but we will see later that SPIP does nonetheless offer a considerable amount of flexibility to overcome this restriction).
When you install SPIP, a set of such templates is offered to you by default. This set is stored in the dist/ directory at the root of your site. As soon as you modify these templates to your own needs, or if you want to install another such set of templates, it’s a good idea to create a new directory called squelettes/ at the same hierarchy level in your site, which will take priority over the standard ones, and which you can then leave in place as they were. For more details about this subject, please read the article Where do I put the template files for my site? .
Whenever a visitor requests a page called http://example.org/spip.php?article3437, SPIP will go to look for a template file called "article.html". SPIP therefore is basing its decision on which template to use based on the URL address itself:
| The URL | will call the template file named |
|---|---|
spip.php?article3437 |
article.html |
spip.php?rubrique143 |
rubrique.html |
spip.php?mot12 |
mot.html |
spip.php?auteur5 |
auteur.html |
spip.php?site364 |
site.html |
With two special cases of note:
- The URL spip.php calls the sommaire.html template to generate and present the site’s home page.
- The URL spip.php?page=abcd calls the abcd.html template. In other words, you can create entire sets of templates which have not been pre-built into the system and name them however you choose to.
This syntax is also used for other kinds of page like the site map or for returning results from a search request, for example: spip.php?page=plan, spip.php?page=recherche&recherche=squirrel.
Whenever SPIP calls a template, it passes a context as "arguments" to that template
In addition, you can see above that the URL can supply other elements than just the name of the template. For example, in spip.php?article3437, the number of the article requested is (3437); and in spip.php?page=recherche&recherche=squirrel, the word searched for is (squirrel).
This constitutes what we call a "context", i.e. one or more "environment variables" that SPIP will provide to the template so that they can be used in the composition of the page. In fact, the article.html template needs to know the number of the requested article so it can go find the matching title, text and other fields from the database. In the same fashion, the recherche.html template needs to know what words the visitor has entered to search for in the database records.
Within the URL, the environment variables appear after the "?" character. When there are several such variables, they are separated by "&" characters.
So the ’URL spip.php?page=recherche&recherche=squirrel has two variables: page and recherche, to which two respective values are assigned: "recherche" and "squirrel".
In the case of spip.php?article5159, SPIP has merely simplified the URL syntax which actually corresponds to : spip.php?page=article&id_article=5159 (and yes, you can try it yourself if you want!). It therefore also has two variables: page, with the value "article", and id_article with the value "5159". These variables enable SPIP to use the data from article 5159 in the database within the article.html template.
How the cache works - made simple
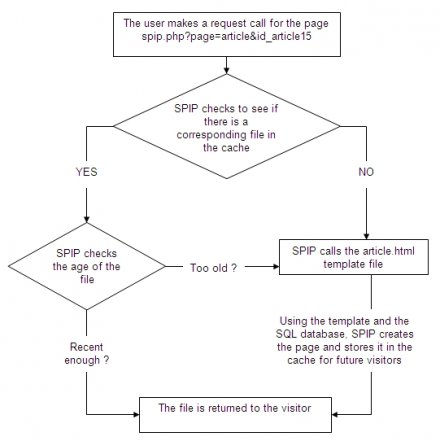
SPIP looks to see if there is a page corresponding to the requested URL already stored in the CACHE
- If the page exists, SPIP checks that it’s not too old.
- If the page is too old, SPIP recalculates it using the appropriate template and data from the MySQL database. It then updates the CACHE before returning that same file back to the user.
- If the page is recent enough, that cached page is immediately returned back to the user.
- If the page doesn’t exist in the cache at all, then it is calculated from the template and MySQL database. It is then also stored in the CACHE before being returned to the requesting user.
When the next visit to that page is made, if the duration between the two visits is sufficiently short, then the recently calculated page stored in the /CACHE is returned without needing to recalculate everything and wait for the database. If the database has actually crashed, then it is always the cached page which is returned, if it has "expired".
Note. We can see here that each page for the site is cached individually, and each recalculation is provoked by a visit to the site. There is generally not any overall recalculation of all pages in a single hit on a regular timed basis (this kind of "major process" often tends to overload the server and sometimes even make it crash).
By default, a page is considered as expired after a period of 3600 seconds. [1]
The .html file
Within SPIP, we call the .html files our squelettes (French for skeleton, and commonly referred to in English as a "template" or "template file"). These are what describe the graphical interface of your site pages, in conjunction with any internal or external, default or customised CSS stylesheet rules that you may specify.
These files are coded directly in HTML, to which are added several instructions telling SPIP where it should position any elements that it extracts from the database (of the style: "put the title here", "show the list of articles with the same topic here", etc.).
The instructions for including and positioning such elements are coded in a special language, which is the subject of this entire on-line user manual. This language, as powerful as it may be, also constitutes the only real major hurdle for learning how to use SPIP. What’s more, most of the keywords used in this language are derived from the French language, which can make learning SPIP additionally more tricky for those not conversant with that language [2].
"Yet another language?" Ah, yes, you will need to learn a new language. Fortunately, its structure is not very complicated, and it can be used to construct complex interfaces very quickly. In comparison to PHP and MySQL, you will see that you do, in fact, gain a lot of time since the SPIP language is actually a lot simpler than those other two. It is therefore a markup language, being one that employs tags quite similar to those in HTML itself.
Note. In the same way that one can learn HTML by taking inspiration from the source code of sites that one visits, you can also inspire yourself from the templates used by other sites that work under SPIP. All you need to do is find the matching ".html" template file. For example, perhaps you would like to see the template for the articles that you are currently viewing now (view the source code to reveal the text of the template).
A different interface for the same site
In addition to the default page formatting for the various types of content on the site (rubrique.html for sections, article.html for articles, breve.html for news items etc.), you are able to create different templates for particular sections of the site and any content belonging to those sections. You only need to create some new .html template files and name them according to the following principle:
- A different interface for a section and its contents (sub-sections, articles, new items, etc.): just append the template file name in question with "-number" (a hyphen followed by the number of that section).
For example, suppose you create a rubrique-60.html file, then it will be applied to section n°60 and to all of its sub-sections instead of the standard rubrique.html. A template file named article-60.html will apply to all articles in section n°60. If that section contains any sub-sections, then any articles in those sub-sections will also adopt the new template. The same would apply for news items in the section with breve-60.html... and so on and so forth.
- An interface for just one single section. (SPIP 1.3) You can also create an interface for one section, but not for its sub-sections. This is done by naming the file with an equal sign instead of the hyphen, i.e. "=number".
For example, creating a file called rubrique=60.html will make it apply only to section n°60 and not to its sub-sections. The same principle applies to article=60.html, breve=60.html, etc. These templates are applied to the contents of section n°60 but not to the contents of any of its sub-sections, which will simply use the default formatting instead.
- An interface for each language supported in a multi-lingual site. This is done by including the two-character language code in the file name just before the .html suffix, e.g. article.en.html, article.fr.html, article.de.html, etc. For full details on this, please read the article on article 2128.
Important note: the number indicated is ALWAYS that of the relevant section. Templates named article-60.html or article=60.html do not relate to article n°60 but to articles contained in section n°60.
What can we put in the .html template files
The .html files are essentially just "text" files, supplemented with instructions for inserting elements from the database.
SPIP only analyses and process these instructions for inserting database elements (coded in SPIP’s own special language); SPIP otherwise completely ignores whatever else is in these files which does not match any of its own known instructions.
The files are therefore essentially HTML. You determine the page formatting, the HTML version you wish to employ, etc. You can obviously include CSS stylesheets, but also JavaScript, Flash... in summary: anything that you would normally put on a Web page anyway.
But you can just as easily (and it’s all just text anyway) create XML files instead (e.g. the backend.html generates XML for RSS feeds).
Even more original: all of the pages returned to the visitor are extracted from the CACHE by a page written in PHP. You may therefore include PHP instructions within your template files, which will be executed when the visit is actually made. Used judiciously, this possibility opens up enormous flexibility to SPIP, so that you can augment it (perhaps by adding a counter, for example) or even alter certain page formatting elements depending on the data extracted from the database.